
Imagine you’re working late into the night, super pumped about implementing this cutting-edge AI model you found in a recent research paper. The paper promises remarkable results, and you’re itching to replicate and maybe even improve them. But soon, you hit a brick wall – the documentation is sparse, and the code is either missing or incomplete.
Sound familiar? This is an all-too-common scenario for developers, making reproducibility a key issue in AI.
Reproducibility basically means the experiment is legit. It gives researchers solid proof that the work is real, providing a strong base to build on for their own experiments. This way, they can focus on tweaking results or adapting the model for specific tasks. But if researchers can’t reproduce the results, or if the results are off, they have to start from scratch and document everything properly. This means they’re stuck redoing the same work and are one step behind what they actually want to test.
You stumble upon an awesome GitHub repo showcasing a killer natural language processing model. It could take your sentiment analysis project to the next level. You clone the repo, run the code, and bam – errors everywhere.
The culprit? The repo relies on an outdated version of a crucial library. Over time, updates to the library have broken everything. Without proper version control or documentation, you’re left fumbling to find compatible versions or, worse, rewriting chunks of code.
You come across an AI model described in a high-impact journal. The results are stellar, and you can’t wait to test it on your dataset. But the paper? It’s a documentation desert. Minimal implementation details, no code.
You spend hours, maybe days, wading through references, trying to decode the methodology. Even when you think you’ve got it, turning those techniques into actual working code is a Herculean task, especially with complex math and data processing.
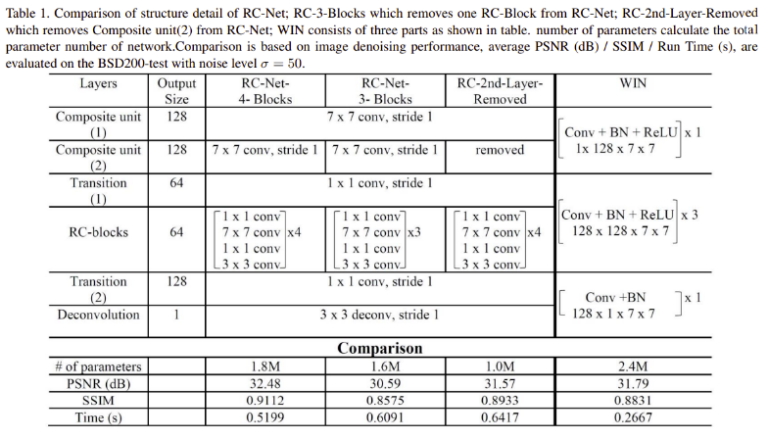
Imagine seeing something like this:

The descriptions of layer parameters were buried in the general text, making it very hard to read. On top of that, the author forgot to describe the parameters for some layers, like normalization layers. As a result, I couldn’t replicate the experiment. I could only attempt to do the general framework.
Alright, we’ve seen the chaos that poor documentation can unleash in AI projects. Now, let’s cut to the chase and talk about how to dodge these bullets. Right off the bat, you need to document your experiments thoroughly, including hardware specifications, development environment, and model architecture. Below, there is an example of a proper documentation with clear comments and specifications.
And here are some tips that will help you create your own comprehensive documentation for AI models or to make sense of one if you want to replicate the experiment.
Hardware specifications play a crucial role in neural network (NN) development and replication. Whether you’re publishing your NN or attempting to reproduce someone else’s work, understanding and communicating hardware details is essential for ensuring reproducibility and managing expectations.
When publishing your neural network, it’s important to provide detailed hardware specifications. This information helps other researchers and developers estimate training times and performance on their own systems. By sharing these details, you contribute to the reproducibility of your work and enable more accurate comparisons across different setups.
Be aware that the absence of hardware information can pose challenges. Without specific details on computational power and training time, it’s difficult to accurately estimate how the NN will perform on your system. This is because neural network architectures are often optimized for the creator’s specific hardware, which may differ significantly from your own. A practical approach to optimization is to align your data sizes with your processor’s memory capabilities.
However, keep in mind that this is just one aspect of performance tuning. Not all GPUs play nice with every framework. For instance, in Python, you’ll typically need an NVIDIA GPU with CUDA support for smooth sailing. Other setups might work, but they could turn into a compatibility nightmare.
The development environment is a critical aspect of your neural network project. It’s essential to provide comprehensive details about your setup, including:
This information is vital for reproducibility. Without it, other researchers may struggle to recreate your environment, potentially leading to compatibility issues or unexpected results.
For example, TensorFlow recently discontinued GPU support for Windows. This means that newer TensorFlow releases can’t be used for computationally intensive neural networks on Windows systems. While setting up a Linux virtual machine is a potential workaround, it adds an extra layer of complexity for users trying to replicate your work.
If you’re attempting to reproduce a neural network from a publication that lacks version information, consider the following strategies:
When in doubt, don’t hesitate to reach out to the original authors for clarification on their development environment.
When documenting your neural network architecture, thoroughness is key. Consider the following guidelines:
If you encounter an article with incomplete architectural details, consider these approaches:
Remember, the goal is to create or replicate a neural network with as much fidelity to the original design as possible.
Neural networks are growing fast, with new designs and uses popping up all the time. Being able to repeat experiments isn’t just a nice idea – it’s crucial for moving the field forward. By paying attention to how we set up our work, build our models, use data, and measure results, we can make our research stronger and more team-friendly.
In the future, repeating experiments will become even more important. We might see new ways to share our work, places to store data and models, and better tools to compare different approaches. Researchers who start doing this now will be ahead of the game.
As we push AI to do more, we need to make sure our progress is solid and can be checked. The future of neural network research looks bright, and by working together to make our experiments repeatable, we can make the most of it.

