
Scheduled Tasks in Spring: Scaling Challenges, Standard and Non-Standard Solutions
Info Setronica
January 21st, 2025
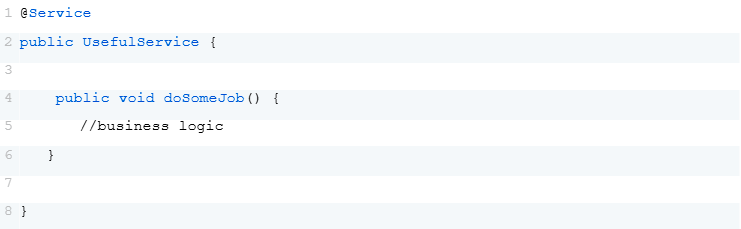
Example of a service
This works well as long as the application is small and operates as a single instance. Typically, the application is deployed within an orchestration system like Kubernetes. As data volume increases, the application starts to scale horizontally, and eventually, the number of application instances can grow significantly.
As a result, each application instance executes the same job, which might not be critical in some scenarios. However, this often leads to an unnecessary strain on system resources and can cause race conditions between job instances. This situation results in excessive resource consumption, increased system errors, and ultimately higher costs for the service owner.
The situation becomes even more complex if the job was developed many years ago, has become part of legacy code, and the original developers are no longer involved in the project. Over time, the application accumulates additional functionality and APIs. Eventually, a decision might be made to scale the application horizontally to meet a conditional Service Level Objective (SLO) for newer features. This decision could be made by individuals who are not thoroughly familiar with the application’s underlying logic.
This is one of those “mystical” scenarios where, despite scaling and allocating additional resources, the application begins to demand even more resources. Often, these resources are provided without fully understanding the underlying issue, due to limitations in system metrics and team expertise.
The most common approach involves using libraries to synchronize jobs across instances by designating a “leader” instance to manage the business logic. Other instances attempt to initiate the job, but report that the launch is canceled if it’s already running elsewhere. Numerous libraries facilitate this process, including Quartz, ShedLock, and JobRunr.
All these libraries have a common requirement: a database is necessary to store the state. Usually, the application already includes a database, and the system tables for the external library are integrated into it.
However, there might not be a traditional database available, or there could be a NoSQL store in use. In such cases, a database must be specifically organized for the task, adding complexity to the system and its support. Also, even with synchronization, each instance still runs its own job instance, which consumes additional resources.
There are occasional situations where local errors or global failures cause all instances to become locked. This requires manual intervention in the system tables of a specific library to restore functionality.
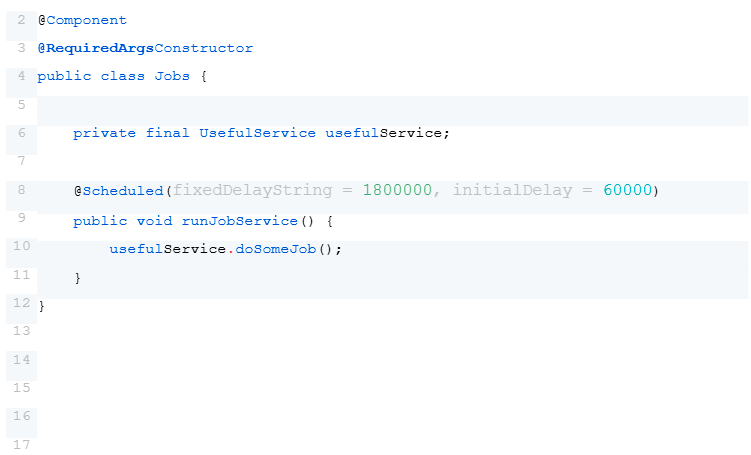
Another concise and effective method for executing jobs is to use an API exposed by the application to handle the task. For instance, an API endpoint in a controller can be used to trigger the required service.
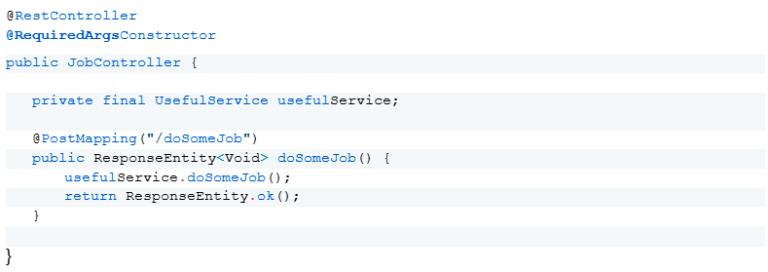
Example of a controller with an API to trigger a job
The procedure is often slow, causing the calling side to potentially encounter a timeout if they wait for a response. To handle this, the implementation is made asynchronous, and an identifier is immediately returned to allow tracking of the job’s progress through system logs.
This approach does not require a database or external library, and the load balancer of the orchestrator decides which service instance will be called. To launch the job, you can configure a Kubernetes CronJob resource.
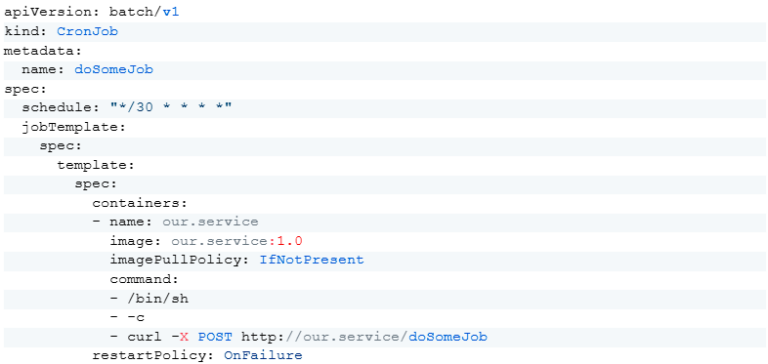
An additional benefit here is the ability to trigger the procedure from another service if, for example, that service needs the results of our service.
However, this approach has its drawbacks, primarily concerning security. Security teams may be reluctant to expose an API for applications that access important and valuable resources. Even if permitted, the API must be protected against unauthorized access, potentially using JWT tokens and a role-based access control system.
Also, the service must be capable of processing these JWT tokens and granting access, which might necessitate modifications to our legacy application—a task that could be constrained by limited resources and time. Despite these challenges, this is a popular approach.
A careful reader familiar with YAML configurations for application deployment might suggest: You can create another deployment configuration and separate the application’s logic using environment variables. This allows a single instance with a new configuration to execute the job, while the main instances continue to serve other functions with the job disabled. Yes, indeed, this is possible.
The main drawback here is the need to support very similar configurations, which will eventually start to live their own lives, and over time, a new developer may not understand the original intent. It may even turn out that the job itself no longer exists, but there is an instance without meaning. Despite this, the approach is often effective, resulting in instances that differ only by suffixes in their names, typically based on a single codebase.
An alternative that avoids most of the previously mentioned drawbacks involves introducing an additional entry point into the application. While this still requires minor modifications to the service and the use of a CronJob, similar to the API launch method, it offers a more streamlined solution.
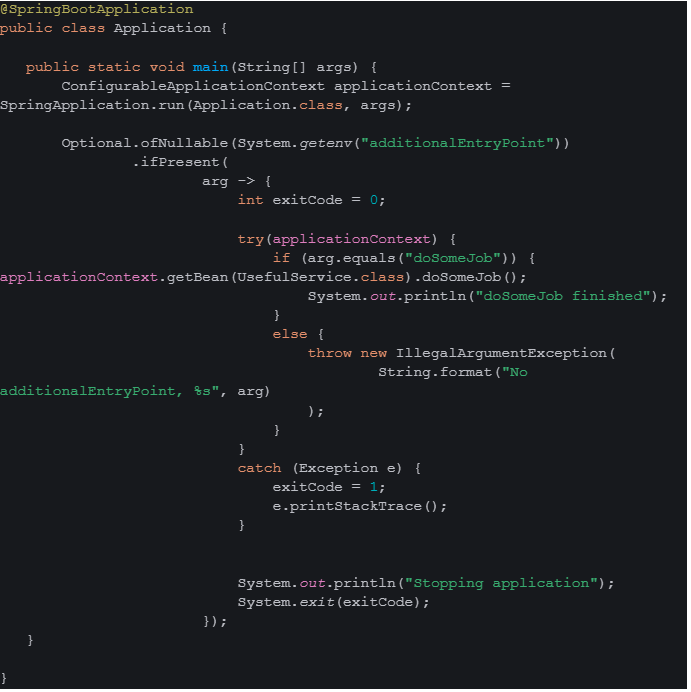

For the existing application, nothing changes since the environment variable for the second entry point is not set, allowing the application to start normally. In the case of a CronJob launch, the logic is activated based on the environment variable’s value. The application context is initialized, the necessary service logic is executed, and the application context is closed afterward. Next, the JVM exits with a success or failure code, marking the completion of the instance’s task.
This approach ensures that the job begins during the pod’s launch, and the instance does not consume resources while inactive, as it ceases to exist between launches. Naturally, this requires some code adjustments, such as removing the @Scheduled annotation from the job and incorporating logic execution at the application’s entry point.
The drawbacks include the inability to implement this for applications running in a container without Spring Boot. However, similar launch logic can be developed for frameworks like Micronaut or JavaSpark if needed. This approach is often called a Swiss Army knife, where each entry point in the application functions as a knife, screwdriver, or scissors, making the method both compact and versatile.
So, there were various methods for organizing periodic tasks, each offering distinct advantages and disadvantages. Rather than identifying a single best approach, the selection should be tailored to the specific circumstances, considering factors such as available resources and the current methodologies employed within the project.
Additionally, it’s important to assess the resource intensity of the tasks to ensure efficient and effective implementation. By carefully evaluating these elements, you can choose the most suitable method for your particular needs.

