An accrual report helps businesses and investors understand the company’s true financial position.
Maksim Sukhodolov | November 26th, 2024


An accrual report helps businesses and investors understand the company’s true financial position.
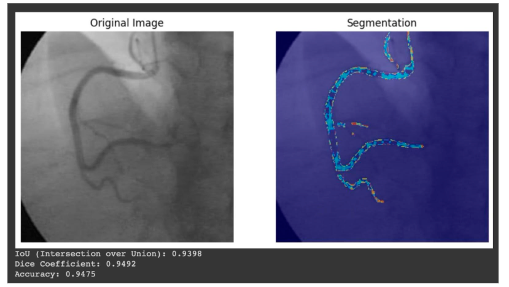
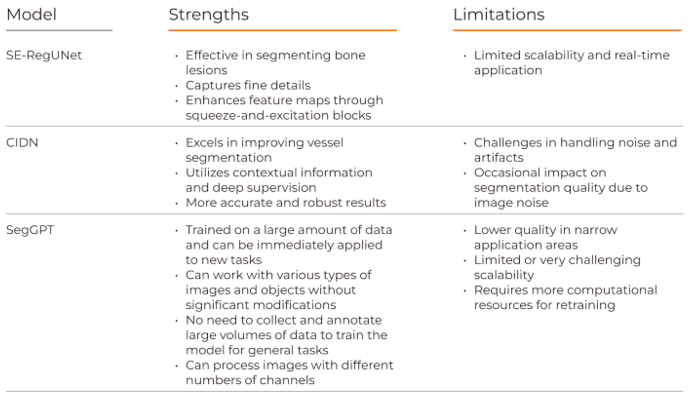
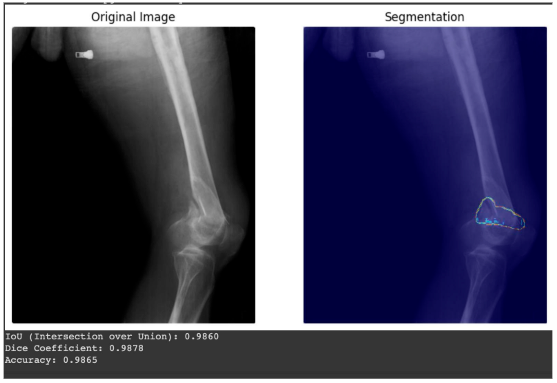
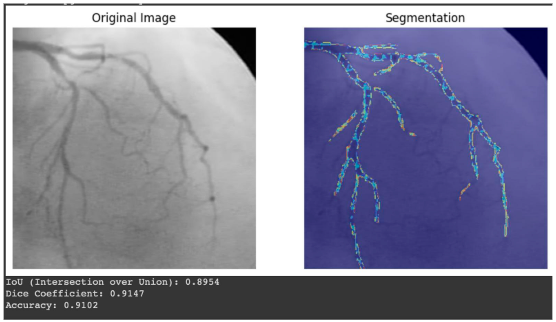
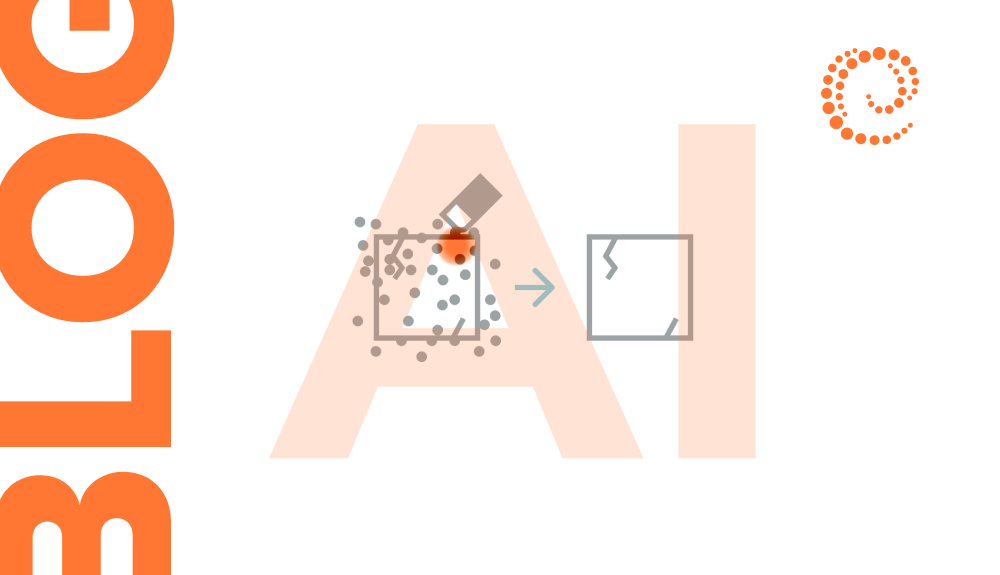
Accurate segmentation of bone structures is crucial for diagnosing fractures, planning surgeries, and monitoring the progression of diseases like osteoporosis.
About a month ago, we launched our very own remote hackathon. Any Setronica developer regardless of their experience, position, or…
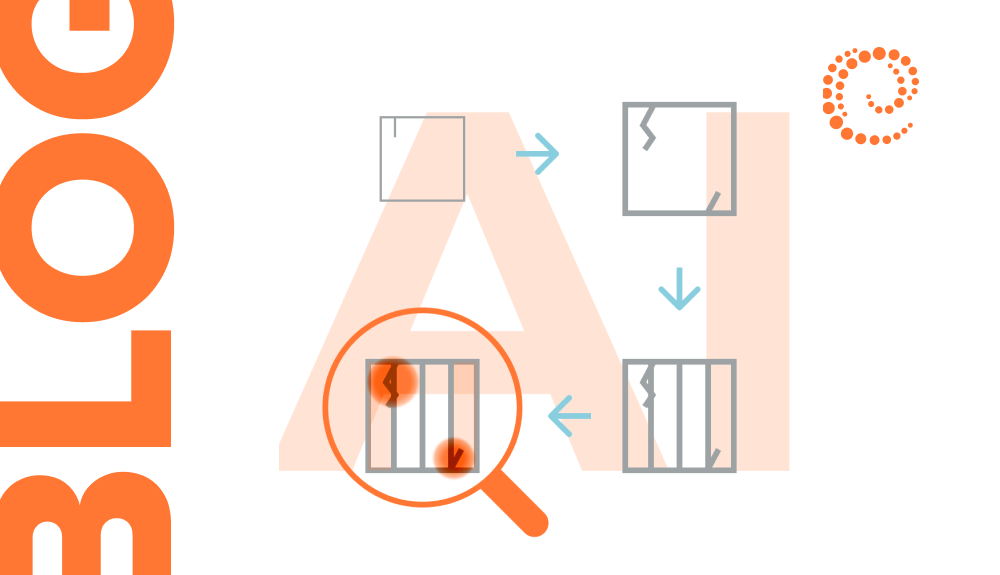
Bone diseases can develop unnoticed and lead to severe consequences if not detected in time. Doctors face numerous X-rays every…

Use Kaggle datasets for research responsibly. Steps: Create an account, explore, check licenses, clean data, conduct research, cite, and share.
