
Mastering Elasticsearch Indexing: How Setronica Fine-tuned Search Engine Performance
Info Setronica | June 27th, 2024
Elasticsearch is a search engine that has become a go-to solution for storing, searching, and analyzing large volumes of data. At the heart of Elasticsearch lies its indexing mechanism, which plays a crucial role in determining the performance and effectiveness of the search engine.
This mechanism involves creating a structured representation of the data, known as an index. It includes breaking down the raw data into individual terms, analyzing their relevance, and storing them in a highly optimized data structure called an inverted index. By doing so, Elasticsearch can quickly locate and retrieve relevant documents based on user queries, providing near real-time search capabilities.
One of the key advantages of Elasticsearch indexing is its ability to handle various data formats, including structured, semi-structured, and unstructured data. This flexibility allows organizations to index and search through a wide range of data sources, such as logs, documents, databases, and even real-time data streams, enabling them to gain valuable insights and make data-driven decisions.
Common Challenges With Elasticsearch Indexing
While Elasticsearch indexing offers numerous benefits, it also presents several challenges that can impact search engine performance if not addressed properly:
- Managing the trade-off between indexing speed and query performance. Indexing large volumes of data can be resource-intensive, and if not optimized correctly, it can lead to slow indexing times and potential bottlenecks in the search engine’s performance.
- Handling dynamic data structures and evolving schemas. As data sources and requirements change over time, the index mappings and analysis configurations may need to be updated to maintain optimal search engine performance. Failure to do so can result in inaccurate search results, decreased relevance, and potential data loss.
- Scalability. As the volume of data grows, the number of indices and shards can increase, potentially leading to resource contention and performance degradation. Proper planning and configuration are essential to ensure that the search engine can scale horizontally and vertically to meet the growing demands of data processing and querying.
Tackling the Slow Search Performance Issue
As Setronica uses Elasticsearch in its projects, the slow search performance becomes a serious issue. Given that search is one of the most heavily loaded services in apps, and it could take between 3 and 5 seconds or more for response, this situation becomes even more critical.
To uncover the root cause, let’s examine the search architecture of an app that connects users to goods and services nearby:
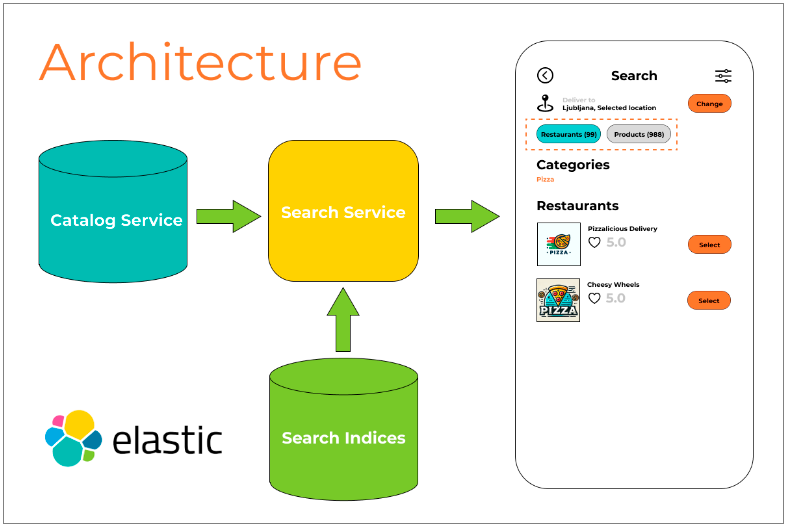
- Initial search in Elasticsearch: When a search query for sellers, products, or both is sent to the Search API, it first searches the Elasticsearch indices containing the required data.
- Relevance and availability check: The results found in Elasticsearch are not fully relevant, as many of them may actually be unavailable. Therefore, the next step involves querying the Catalog service.
- Distance calculation: The Catalog service uses geolocation data to calculate the actual delivery distances between sellers and the user. This helps in filtering out offers that are beyond the maximum delivery distance for the area or the personal distance limit set by a specific seller.
- Database query: The service first needs to retrieve data based on the received offers using flexible criteria.
- Excessive resource consumption: A lot of time and resources are spent selecting the appropriate data from the initially excessive input data to form a relevant search result for the user. Additionally, this creates unnecessary extra load on other related services.
It was necessary to somehow reduce the redundancy of the data coming from the search service for processing the search query. So, we’ve come up with an idea how to make the responses from Elasticsearch more relevant.
Setronica’s Solution
To enhance efficiency, the client search query should incorporate geodata from the outset, allowing the Catalog service to filter out sellers based on distance directly within Elasticsearch.
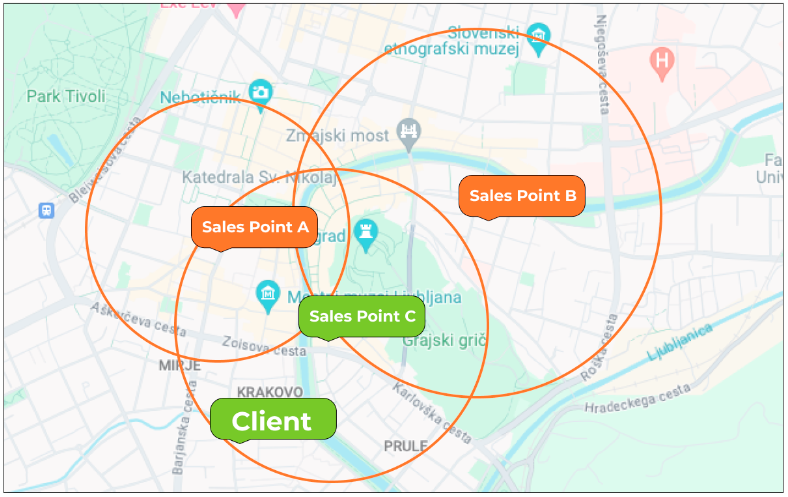
1. Actual Distance
Elasticsearch distance calculations are based on the great-circle distance, which can sometimes lead to discrepancies when comparing with actual street distances. The example below shows the difference between calculating the distance as the crow flies and the actual street distance.
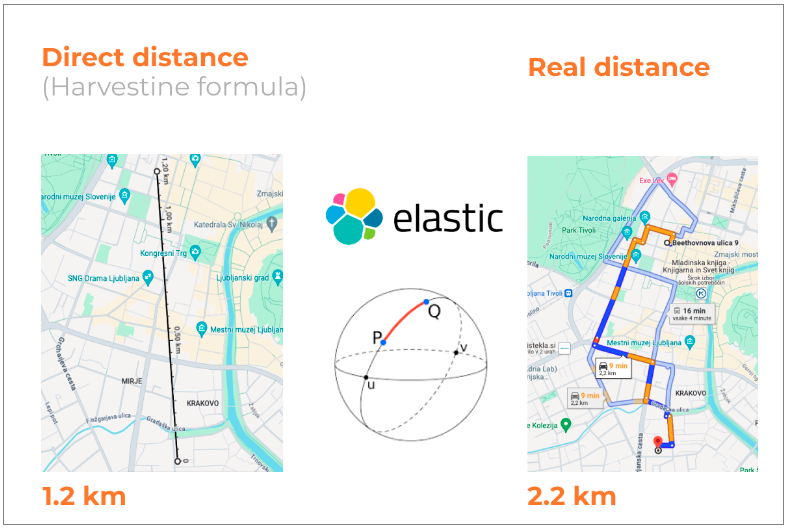
Generally, this discrepancy is not critical because the straight-line distance is always less than or equal to the actual distance. For example, if the maximum delivery distance is set to 1 km and the straight-line distance from the client to the seller is 1.2 km, the actual distance will be greater, ensuring the seller does not appear in the search results.
However, this can create some redundancy. For instance, if the maximum distance is set to 1.5 km, the seller may pass the Elasticsearch query but will be filtered out later by the Catalog service. Nonetheless, this redundancy should not significantly impact the final results.
2. Sales Points Coordinates
To enhance distance filtering, we need the coordinates of sales points within specific operation areas. As part of the recent implementation of the sorting functionality, the merchant index now includes coordinates for all sales points. These coordinates are used to organize search offers, and there is an array of coordinates for sales points across all operation areas.
Given this data, why not use it for distance filtering?
While it might seem logical to use these coordinates for distance filtering to ensure sales points close to the client are not excluded, the maximum distance is a dynamic parameter. It can vary between different areas and can be redefined by the seller for each specific area. This creates a one-to-many relationship between the seller and their delivery settings within a specific delivery area.
Fortunately, this relationship is already reflected in the merchant index structure. For each seller record in the index, there are nested records for each operation area where the seller has at least one active sales point.
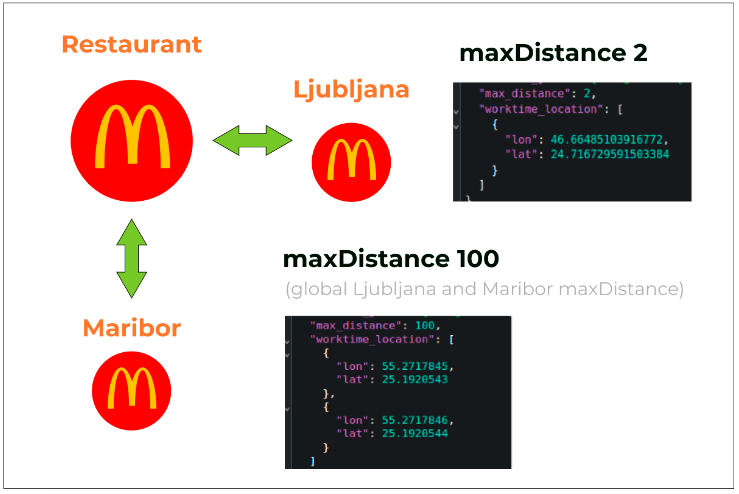
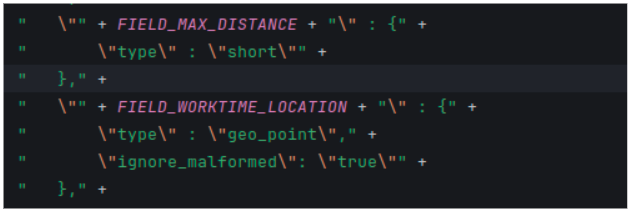
Thus, we added two additional fields to the seller index structure:
- max_distance: A field for storing the value of the maximum distance in this operationArea according to global or redefined settings for this area.
- worktime_location: A field for storing an array of coordinates of sales points specifically in this operationArea.
3. Current Data Delivery
The third challenge involved ensuring the delivery of up-to-date data on distance settings and sales point coordinates to the index. Updating the sales points was straightforward – simply by updating the Data Transfer Object (DTO) for indexing with the required fields. Once this was done, the data began to flow to the index through the existing indexing mechanism via a queue.
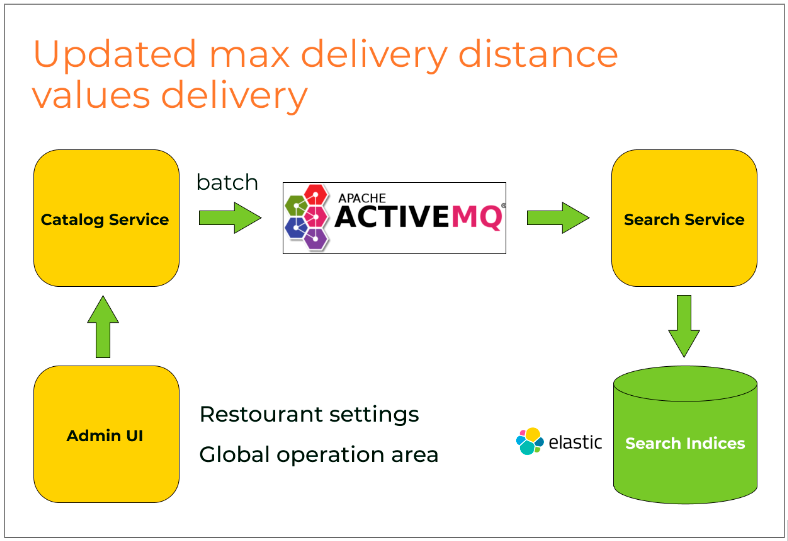
Updating Distance Settings
To update delivery distance settings, the mechanisms for modifying delivery parameters within the operation area and the seller’s personal settings were refined. When these settings were changed, events were triggered to reindex the merchants in the affected area, ensuring that the index remained current.
Implementation of Filtering
With all the necessary data now in the index, the next step was to apply the appropriate filtering function to achieve the desired results. However, the filtering needed to occur within a subquery, and there was no standard, ready-made solution for filtering by a calculated dynamic value. This meant, a custom script for the query was needed.
Moreover, it became evident that the Elasticsearch arcDistance function could not compute distances for fields that are arrays of coordinates. Therefore, we had to manually implement the minimum distance calculation using the Haversine formula and perform the filtering based on the maximum delivery distance within the same script.
Here is an example of a script that you can use as a base for your solutions. The resulting code will depend on your parameters and data.
public static ScriptQueryBuilder buildFilterMerchantWorktimeByMaxDistanceScript(@Nonnull GeoPointDto geoPointDto) {
String source = ” <<double dist=Double.MAX_VALUE;
for (int i=0; i<doc[‘venues.location’].values.length; i++) {
double lat1 = doc[‘venues.location’][i].lat;
double lon1 = doc[‘venues.location’][i].lon;
double lat2 = 77.096080;
double lon2 = 28.51818;
double TO_METERS = 6371008.7714D;
double TO_RADIANS = Math.PI / 180D;
double x1 = lat1 * TO_RADIANS;
double x2 = lat2 * TO_RADIANS;
double h1 = 1 – Math.cos(x1 – x2);
double h2 = 1 – Math.cos((lon1 – lon2) * TO_RADIANS);
double h = h1 + Math.cos(x1) * Math.cos(x2) * h2;
double cdist = TO_METERS * 2 * Math.asin(Math.min(1, Math.sqrt(h * 0.5)));
dist = Math.min(dist, cdist);
}
return dist;>>”;
Map<String, Object> params = new HashMap<>(2);
params.put(LAT_PARAM, geoPointDto.getLat());
params.put(LON_PARAM, geoPointDto.getLon());
Script script = new Script(Script.DEFAULT_SCRIPT_TYPE, PAINLESS_PROGRAMMING_LANG, source, params);
return QueryBuilders.scriptQuery(script);
}
We sequentially compute the distance from each sales point coordinate to the client. If the distance is less than the specified threshold, we consider the offer relevant. This additional condition is applied to all queries in the merchant index as a must among all other criteria:

This approach allows us to instantly filter out results that are irrelevant in terms of delivery distance for specific sellers.
4. Product Indexing
The product index is separate and does not include coordinates, with data volume being significantly larger. Adding sales point coordinates to product records would be overly complex. Previously, unavailable products were filtered out by checking the sellers of the identified products through another service. However, now this process is streamlined within the Search service itself.
After retrieving products from the index, an additional lightweight query is executed against the merchant index using the product seller identifiers extracted from product index records, applying our custom filtering script. This ensures that products from unavailable sellers are immediately excluded, significantly reducing the data sent to the Catalog service.
Implementation & Results
One of Setronica’s long-term clients was experiencing slow search performance. To address this, Setronica implemented various features in the client’s app and conducted load testing on a dataset equivalent to the production environment:
- Initially, the search service was tested with the filtering implementation through the index turned off. The response times varied between 1.5 to 5 seconds.
- Next, the index was populated with data, and filtering through the index was enabled.
- Following this change, almost all queries completed within 1 second, with half of them executing in just 0.5 seconds.
The load testing results were so impressive that the feature was enabled in the production environment. After some time in production, an analysis of the search API response times revealed a significant improvement, with clients now receiving responses almost instantly:
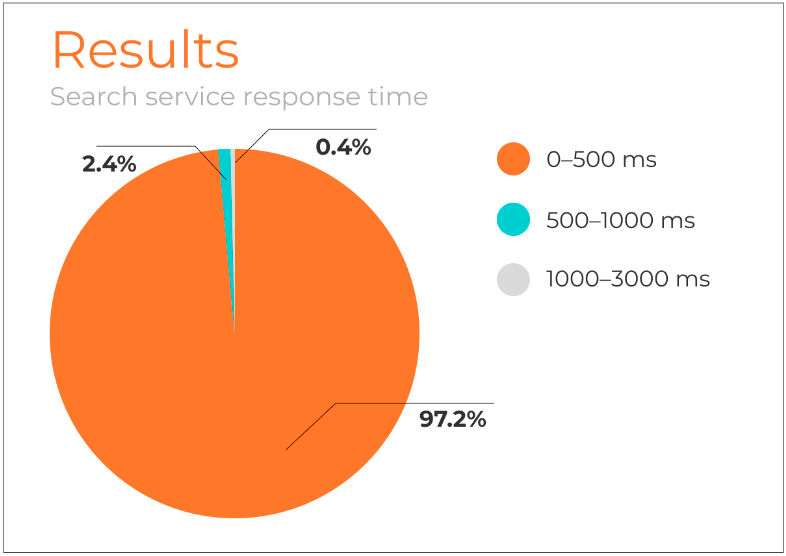
Conclusion
The enhancements implemented by Setronica in the client’s app have significantly improved search performance for their long-term client. By refining the filtering mechanism and optimizing the indexing process, Setronica was able to reduce response times dramatically. The systematic approach – starting from load testing in a controlled environment to enabling features in production – demonstrated a clear reduction in database load and a substantial increase in query efficiency.
The results speak for themselves: the client now enjoys near-instantaneous search responses, enhancing user experience and operational efficiency. This case study showcases how thoughtful implementation of advanced search functionalities can solve performance issues and deliver tangible benefits.
More case studies
- Mastering Elasticsearch Indexing: How Setronica Fine-tuned Search Engine Performance
 Elasticsearch is a search engine that has become a go-to solution for storing, searching, and analyzing large volumes of data.
Elasticsearch is a search engine that has become a go-to solution for storing, searching, and analyzing large volumes of data. - IT Operations Management: How to Monitor Remote Workstations for Tech Issues
 Workstations are specialized computers designed to handle tasks that conventional computers would struggle with.
Workstations are specialized computers designed to handle tasks that conventional computers would struggle with. - Crucial Insights: Why Monitoring Modular Data Centres Matters
 The power industry encounters obstacles when distributing electricity across extended distances because of considerable losses along transmission lines.
The power industry encounters obstacles when distributing electricity across extended distances because of considerable losses along transmission lines. - A Tailored Metaprograming Approach to Pre-Mentoring Preparation — How Does It Work?
 Imagine offering mentoring services to your team, where effectiveness is not just a goal but a guarantee.
Imagine offering mentoring services to your team, where effectiveness is not just a goal but a guarantee. - Empowering Change Through The Ethical Social Network
 Ethical Social Network: MVP revolutionizes nonprofit fundraising, ensuring transparency and compliance for impactful change.
Ethical Social Network: MVP revolutionizes nonprofit fundraising, ensuring transparency and compliance for impactful change. - Streamlining Infrastructure for a Social Connection Platform
 Streamlining infrastructure transformed a California company’s growth, embracing Terraform for efficient scaling and rapid deployment.
Streamlining infrastructure transformed a California company’s growth, embracing Terraform for efficient scaling and rapid deployment.
Let’s start building something great together!
Contact us today to discuss your project and see how we can help bring your vision to life. To learn about our team and expertise, visit our ‘About Us‘ webpage.
Recent Posts
- How to Use Kaggle Datasets for Research: 10 Essential Steps
- From University English Teacher to Language Training Specialist: A Journey into the Business World
- Stress Interviews: Hot Trend or Red Flag Central?
- Ensuring Reproducibility in AI Experiments
- Culture-Driven Coding: Leading IT Teams in a Global Landscape
